coder
Kafka
Kafka如何保证顺序
Producer 端: Kafka 的发送端发送消息,如果是默认参数什么都不设置,则消息如果在网络没有抖动的时候,可以一批批的按消息发送的顺序被发送到 Kafka 服务器端。但是,一旦网络波动了,则消息就可能出现失序。所以,要严格保证 Kafka 发消息有序,首先要考虑同步发送消息。
- 设置消息响应参数 acks为-1(或者为all)
- 设置enable.idempotence = true幂等特性这个特性可以给消息添加序列号,每次发送,会把序列号递增 1。开启了 Kafka 发送端的幂等特性后,我们就可以设置max.in.flight.requests.per.connection = 5这样,当 Kafka 发消息的时候,由于消息有了序列号,当发送消息出现错误的时候,在 Kafka 底层会通过获取服务器端的最近几条日志的序列号和发送端需要重新发送的消息序列号做对比,如果是连续的,那么就可以继续发送消息,保证消息顺序。
Broker 端: 设置一个分区
Consumer 端: 一个consumer
架构
如上图所示,有2个Broker,4个Partition,每个Partition都是leader-follower结构,follower只负责同步leader的数据,leader故障时选取一个ISR(in-sync replica)作为leader。
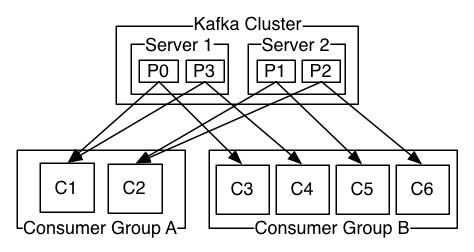
消费组机制 一个partition只能分配给一个消费组的一个consumer,也就是说一个消费组中,不可能2个consumer去消费一个partition。所以需要注意consumer数量,不要多于partition数量。
producer ACK机制 Kafka的ack机制,指的是producer的消息发送确认机制,这直接影响到Kafka集群的吞吐量和消息可靠性。而吞吐量和可靠性就像硬币的两面,两者不可兼得,只能平衡。ack有3个可选值,分别是1,0,-1(all)。
- ack=1,简单来说就是,producer只要收到一个分区副本成功写入的通知就认为推送消息成功了。这里有一个地方需要注意,这个副本必须是leader副本。只有leader副本成功写入了,producer才会认为消息发送成功。 注意,ack的默认值就是1。这个默认值其实就是吞吐量与可靠性的一个折中方案。生产上我们可以根据实际情况进行调整,比如如果你要追求高吞吐量,那么就要放弃可靠性。
- ack=0,简单来说就是,producer发送一次就不再发送了,不管是否发送成功。
- ack=-1(all),简单来说就是,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。
min.insync.replicas
broker端有min.insync.replicas配置,比如副本数为3,min.insync.replicas配置2,表示至少2个ISR(包括leader)确认收到消息,leader才回复producer消息提交成功。min.insync.replicas只有在producer的ack配置为-1(即all)才会生效。
min.insync.replicas默认值是1,可以在创建topic指定(跟着topic走),也可以在配置文件中指定(所有topic使用)。
这个配置的目的是保持提升可用性,如果一个副本挂了,仍然可以工作。
每个partition的leader或者follower都有LEO(日志末端位移),HW(高水位):
| —-已提交数据—- | (HW)—–未提交数据—— | (LEO) |
leader的HW决定了消费者可以消费到的数据,跟不上leader速度(消息数量落后leader太多)的ISR或者超过一定时间未从leader拉取消息将会被剔除,数据同步跟上之后会再次成为ISR。
发送数据时,当所有ISR确认收到数据后,leader才commit。
如果一个消费组的消费者数量超过了partition数量,则会有空闲的消费者,即在一个消费组里,一个partition只能被一个消费者消费。
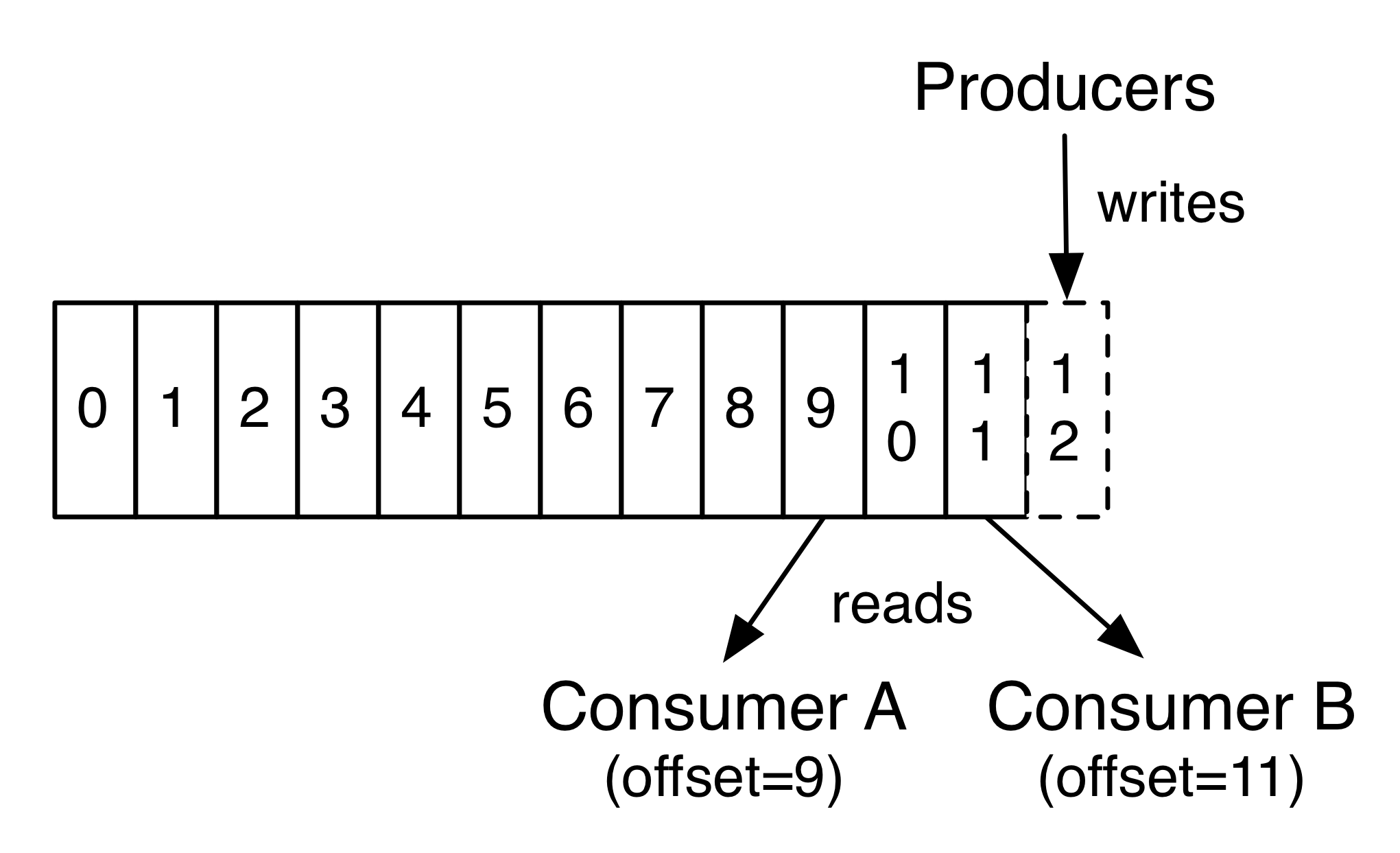
如下图所示,每个partition都是一个有序的不可变的记录序列,每个消息都会保留在磁盘一定的时间,在保留时间内,消费者都会消费到,超过保留时间,消息将会从磁盘删除。
Rebalance is the re-assignment of partition ownership among consumers within a given consumer group. Remember that every consumer in a consumer group is assigned one or more topic partitions exclusively.
A Rebalance happens when:
- a consumer JOINS the group
- a consumer SHUTS DOWN cleanly
- a consumer is considered DEAD by the group coordinator. This may happen after a crash or when the consumer is busy with a long-running processing, which means that no heartbeats has been sent in the meanwhile by the consumer to the group coordinator within the configured session interval
- new partitions are added
高吞吐
Page Cache和内存映射文件
为了提高磁盘访问速度,现代操作系统在磁盘上构建一层page cache作为缓存,在读取磁盘时,一般会进行磁盘预读,即读取随后几个页面大小的磁盘到page cache。写磁盘时会写page cache,page cache会异步刷新到磁盘上。
kafka使用Memory-mapped file(内存映射文件)提高磁盘访问速度,即将page cache映射到进程地址空间,避免了数据从内核拷贝到用户空间,应用可以直接像访问内存一样访问文件。
Zero Copy
发送文件一般涉及到如下几步:
- 读取磁盘到page cache(read)
- 将page cache拷贝到用户空间内存(read)
- 将用户空间内存拷贝到socket缓存(send)
- 将socket缓存的数据发送到网卡缓存(send)
使用Linux的sendfile api可以降低系统调用次数和内存拷贝次数,即零拷贝:
- 读取磁盘到page cache
- 将page cache映射到socket缓存
- 将socket缓存的数据发送到网卡缓存
根据时间戳或者offset回溯消息
Properties props = new Properties();
props.put("bootstrap.servers", "xxxx:port");
props.put("group.id", "cgi-xxx");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
String topic = "xxx_biz";
try {
// 获取topic的partition信息
List<PartitionInfo> partitionInfos = consumer.partitionsFor(topic);
List<TopicPartition> topicPartitions = new ArrayList<>();
Map<TopicPartition, Long> timestampsToSearch = new HashMap<>();
DateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date now = new Date();
long nowTime = now.getTime();
System.out.println("当前时间: " + df.format(now));
long fetchDataTime = nowTime - 1000 * 60 * 300; // 计算30分钟之前的时间戳
for(PartitionInfo partitionInfo : partitionInfos) {
topicPartitions.add(new TopicPartition(partitionInfo.topic(), partitionInfo.partition()));
timestampsToSearch.put(new TopicPartition(partitionInfo.topic(),
partitionInfo.partition()), fetchDataTime);
}
consumer.assign(topicPartitions);
// 获取每个partition一个小时之前的偏移量
Map<TopicPartition, OffsetAndTimestamp> map = consumer.offsetsForTimes(timestampsToSearch);
OffsetAndTimestamp offsetTimestamp = null;
System.out.println("开始设置各分区初始偏移量...");
for(Map.Entry<TopicPartition, OffsetAndTimestamp> entry : map.entrySet()) {
// 如果设置的查询偏移量的时间点大于最大的索引记录时间,那么value就为空
offsetTimestamp = entry.getValue();
if(offsetTimestamp != null) {
int partition = entry.getKey().partition();
long timestamp = offsetTimestamp.timestamp();
long offset = offsetTimestamp.offset();
System.out.println("partition = " + partition +
", time = " + df.format(new Date(timestamp))+
", offset = " + offset);
// 设置读取消息的偏移量
consumer.seek(entry.getKey(), offset);
}
}
System.out.println("设置各分区初始偏移量结束...");
while(true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.println("partition = " + record.partition() +
", offset = " + record.offset()+", msg="+record);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
Kafka配置
consumer
- max.poll.interval.ms: 拉取消息得最大间隔,即消息处理得最大时间,否则consumer会抛异常
- session.timeout.ms: consumer coordinator和consumer的心跳,超过这个时间,则会触发rebalance.
Kafka Connect
Connect用在多数据源之间进行数据转换,比如将Oracle的数据转到Mysql,用户自定义Source(拉取)任务(connector)和Sink(转存)任务,将任务提交到connect服务(connect是一个独立配置、启动的服务),connect调度Source和Sink任务,通过Kafka的消息队列功能,完成数据转换。具体可以参考kafka connect文档(https://zditect.com/code/kafka-connect-tutorial.html)。 connect提供Standalone和Distributed模式,对外提供Restful的接口,实现对connector的管理。